A ‘tidyverse’ approach to simulation models
I am a big fan of Rstudio’s (mainly led by Hadley Wickham) series of R packages known as the ‘tidyverse’. The packages modernise much of R’s functionality to better deal with moderately large databases and programming.
There is even a tidyverse package now, so you can hit up all their packages with one short library(tidyverse) call.
If you are into programming (ie doing more than just running a couple of linear models) then I recommend you check out the purrr package. It provides many functions that basically make looping easier and faster to code.
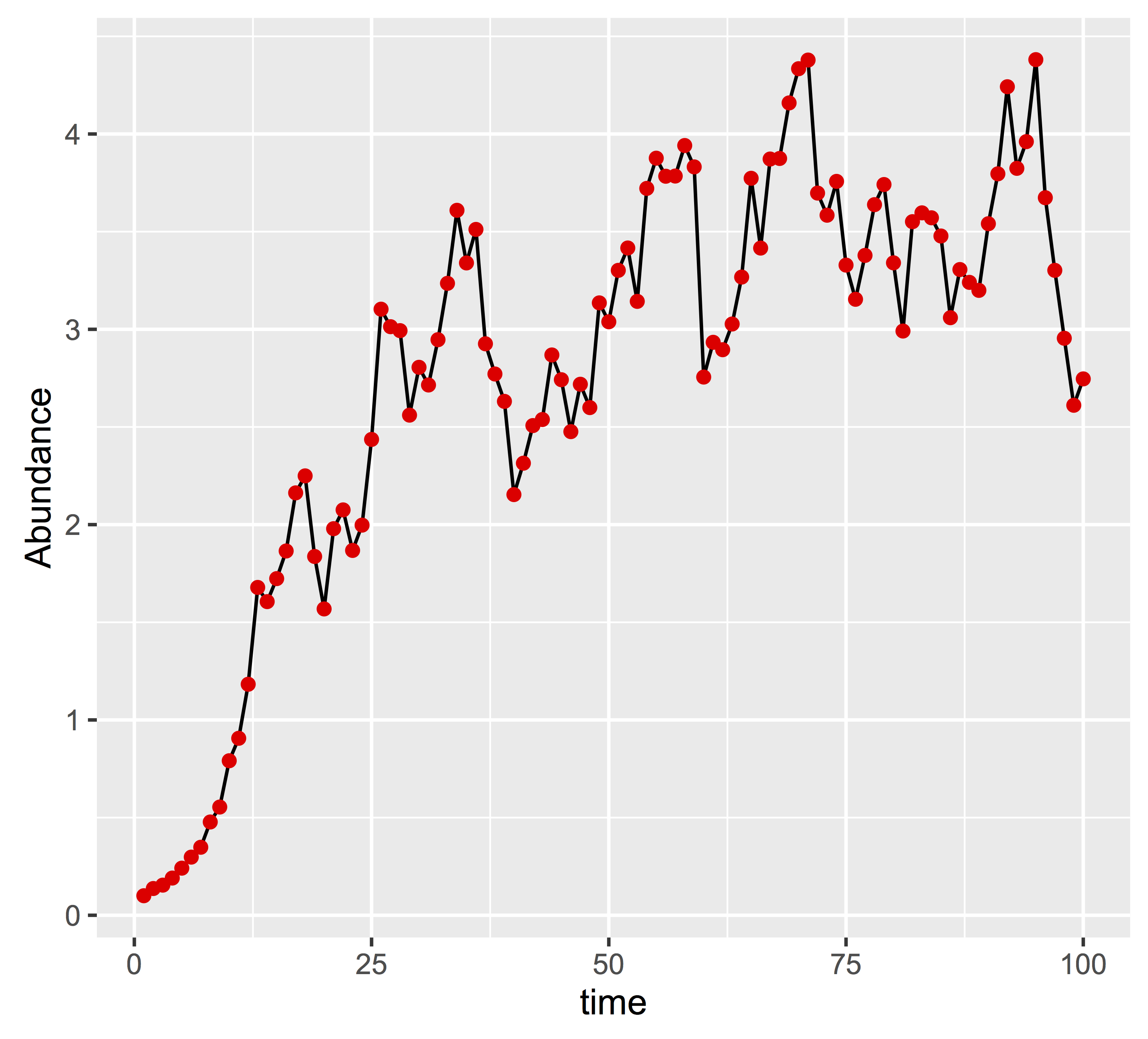
A stochastic simulation of population size generated using a loop (black line) and the accumulate function from purrr package (red points)
Here I explore how to use purrr to create a simple simulation model where a state variable at a time depends on its past state.
Skipping to my main point, it turns out that purrr may be more convenient in that it saves typing over writing loops. However, in this case the purrr function required more computational time.
The model we will use to test purrr will create stochastic simulations of population size that look something like is pictured.
First load the tidyverse package (or just purrr) and specify some parameters.
library(tidyverse)
#timesteps
tmax <- 100
#pop growth
r <- 1.2
#capacity
K <- 20
#abundance sd
sdev <- 0.1
Now we generate a series of random numbers. We will multiply these by population size at each time-step to create stochastic variation:
set.seed(42) #so we get the same numbers
pmult <- exp(rnorm(100, sd = 0.1))
Now, write a function that specifies how abundance changes at a single time point:
popmod <- function(N, popmult, r, K){
N * (r - r*(N / K))*popmult
}
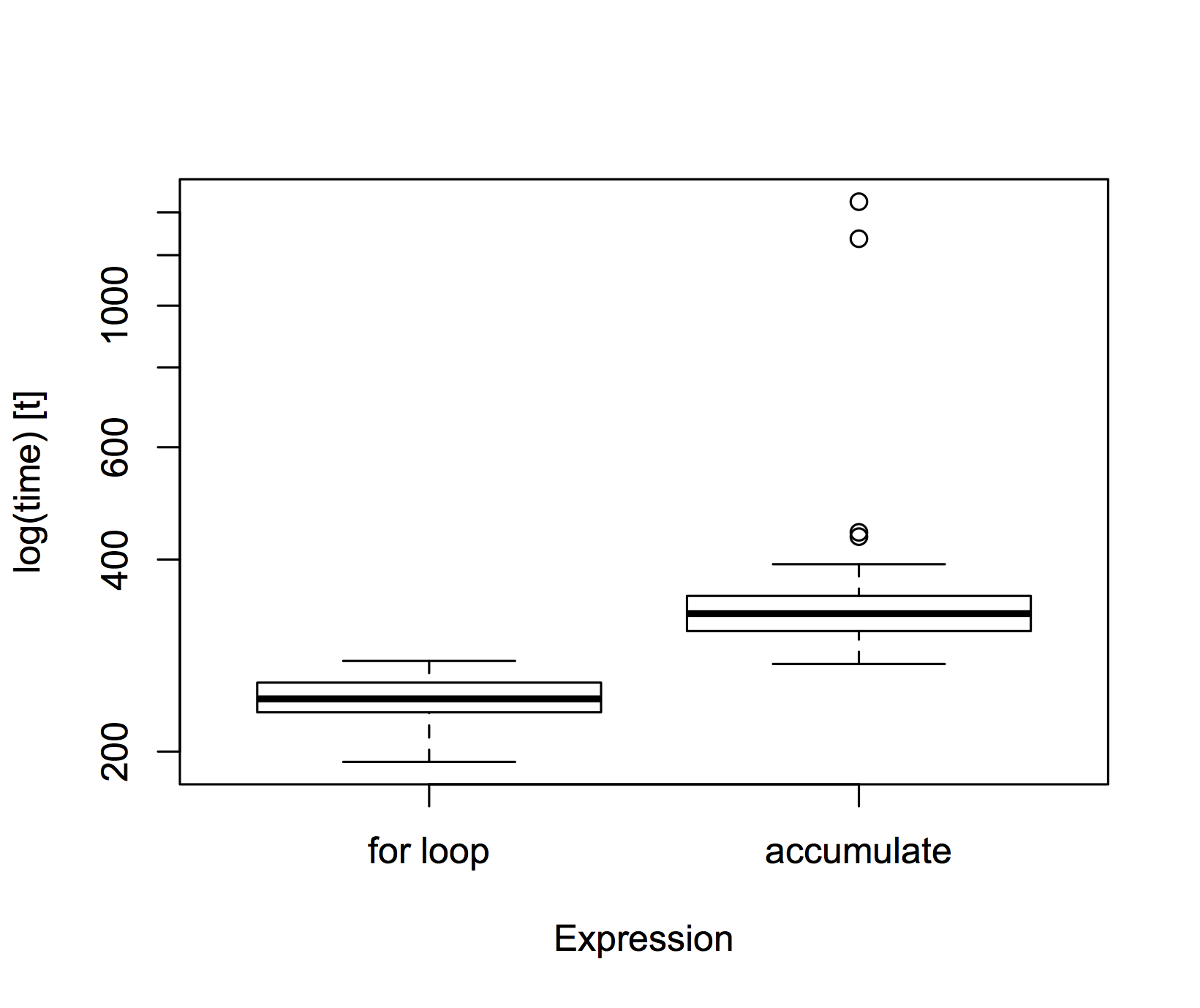
The standard for loop was faster than accumulate
Now, let’s implement a function that uses a normal for loop to loop over abundances at time.
f <- function(pmult, tmax){
x2 <- rep(NA, tmax)
x2[1] <- 0.1
for (t in 2:tmax){
x2[t] <-
popmod(x2[t-1],pmult[t-1], r, K)
}
x2
}
We can use our new function to simulate abundance at time like this (as pictured):
loopabund <- f(pmult, tmax)
Now for the purrr equivalent. We will use the accumulate function, which loops over a vector sequentially. Basically we would want to do this because it saves typing. Arguably it can also make your code more readable (assuming your reader knows how accumulate works).
accumulate(pmult, ~popmod(.x, .y, r = r, K = K), .init = 0.1)
Accumulate works by taking a vector then iteratively applying a function. In this case we have applied it to our popmod function.
We have written our function as a formula, proceeded by ~, for convenience. This means we can use the .x and .y arguments. The .x is the argument that will be accumulated (ie population size). The .y is the argument that we iteratively apply the function to - in this case the vector of multiples.
We can wrap our use of accumulate in a function, for convenience later.
f2 <- function(pmult) {
x3 <- accumulate(pmult, ~popmod(.x, .y, r = r, K = K), .init = 0.1)
x3
}
Now we have two ways to simulate the same population. Let’s check they are the same by plotting them over each other:
accabund <- f2(pmult)[1:tmax]
#put our two simulations in a data.frame
datp <- data.frame(time = 1:tmax,
loopabund = loopabund,
accabund = accabund)
ggplot(datp, aes(x = time, y = loopabund)) +
geom_line() +
geom_point(aes(y = accabund), color = 'red') +
ylab("Abundance")
So they are equivalent. We can then test for computational efficiency using the microbenchmark package:
microbenchmark::microbenchmark(f(pmult, tmax), f2(pmult)) %>% boxplot()
It turns out that the for loop was about 40% faster than the purrr function aggregate. Such a time difference is trivial for this problem, but for more complex models could make a big difference. So the choice between purrr and base R comes down to whether you want to emphasise ease of coding and readability or speed of computation.