Smoothing a time-series with a Bayesian model
Recently I looked at fitting a smoother to a time-series using Bayesian modelling. Now I will look at how you can control the smoothness by using more or less informative priors on the precision (1/variance) of the random effect.
We will use the same dataset as the last post.
To control the priors for an R-INLA model, we
use the hyper argument (not hyperactive, but hyper-parameters):
library(INLA)
f3 <- y ~ 1 + f(z, model = "rw1", scale.model = TRUE,
hyper = list(theta = list(prior="pc.prec", param=c(1,0.01))))
We can control the level of smoothing through param=c(theta1,0.01). A
value of 1 (theta1) is a reasonable starting point (based on the INLA
documentation).
Lower values will result in a smoother fit.
The pc.param stands for Penalized complexity parameters (you could
also use a loggamma prior here). My understanding of penalized
complexity priors is that they shrink
the parameter estimate towards a ‘base-model’ that is less flexible. In
this case, we are shrinking the standard deviation (AKA the flexibility)
of the random walk (ie how much sequential data points deviate from each
other) towards zero. Ultimately if we set theta1 near zero the smoother
will be a straight line.
So let’s fit three models with theta1 varying and see how it affects the smoothness of the fit:
f1 <- y ~ 1 + f(z, model = "rw1", scale.model = TRUE,
hyper = list(theta = list(prior="pc.prec", param=c(0.01,0.01))))
f2 <- y ~ 1 + f(z, model = "rw1", scale.model = TRUE,
hyper = list(theta = list(prior="pc.prec", param=c(0.05,0.01))))
f3 <- y ~ 1 + f(z, model = "rw1", scale.model = TRUE,
hyper = list(theta = list(prior="pc.prec", param=c(1,0.01))))
m1 <- inla(f1,family = "nbinomial", data = dat,
control.predictor = list(compute = TRUE, link = 1)
)
m2 <- inla(f2,family = "nbinomial", data = dat,
control.predictor = list(compute = TRUE, link = 1)
)
m3 <- inla(f3,family = "nbinomial", data = dat,
control.predictor = list(compute = TRUE, link = 1)
)
Here are the resulting fits:
plot(dat$z, dat$y, col = 'grey80', type = 'l', lwd = 1, xlab = "years", ylab = "Abundance", las = 1)
lines(dat$z, m1$summary.fitted.values$mean, col = "skyblue", lwd = 2)
lines(dat$z, m2$summary.fitted.values$mean, col = "steelblue", lwd = 2)
lines(dat$z, m3$summary.fitted.values$mean, col = "darkblue", lwd = 2)
legend('topright', legend = c("data", "theta1 = 0.01", "theta1 = 0.05", "theta1 = 1"),
lty = 1, col = c("grey80", "skyblue", "steelblue", "darkblue"), lwd = 2)
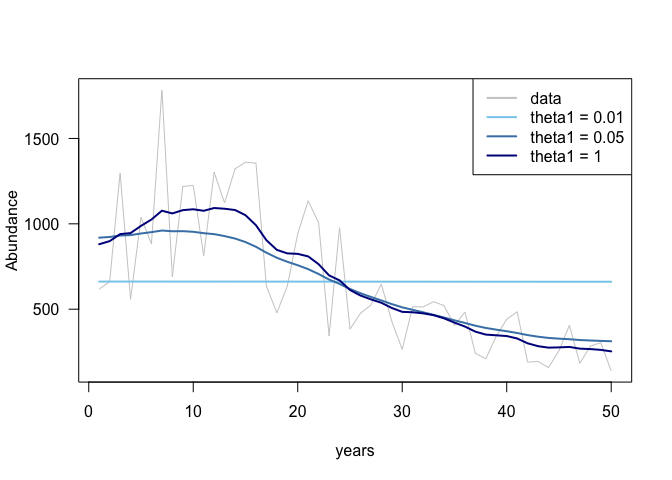
The exact value to use for theta1 will vary depending on our data. If the data are more informative (e.g. a longer time-series) we will have to use a smaller value to create a smoother fit.
dat2 <- list(y = dat$y[1:40], z = 1:40)
m4 <- inla(f2,family = "nbinomial", data = dat2,
control.predictor = list(compute = TRUE, link = 1)
)
plot(dat$z, dat$y, col = 'grey80', type = 'l', lwd = 1, xlab = "years", ylab = "Abundance", las = 1)
lines(dat$z, m2$summary.fitted.values$mean, col = "skyblue", lwd = 2)
lines(dat2$z, m4$summary.fitted.values$mean, col = "steelblue", lwd = 2)
legend('topright', legend = c("data", "theta1 = 0.05, 50 data points", "theta1 = 0.05, 40 data points"),
lty = 1, col = c("grey80", "skyblue", "steelblue"), lwd = 2)
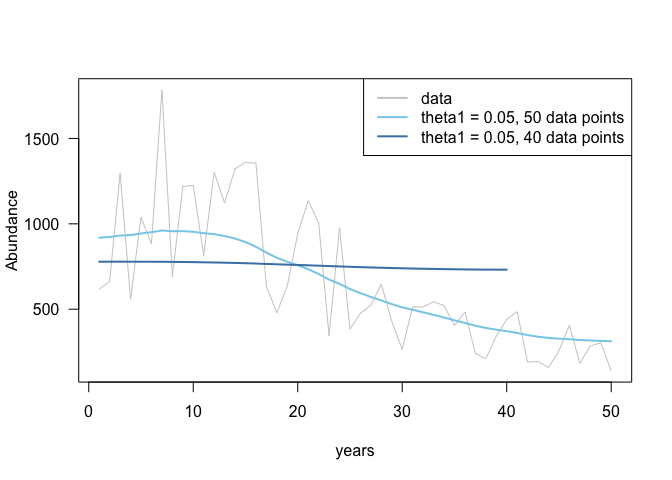
And that is pretty much it. I haven’t read how to choose the ‘optimal’ value of theta. Pragmatically, one could do it with cross validation or perhaps a model selection measure. However, that seems philosophically incorrect, because it is a ‘prior’. There doesn’t seem to be much guidance in the literature about how to choose priors for smoothing. Message me on Twitter if you have seen an example of doing this.
It is amazing to see how the use of priors in statistics has changed since I first learned about Bayesian statistics. It used to be that you would use informative priors only if you had strong prior beliefs about a parameter estimate, such as from expert elicitation, or repeat experiments. If you didn’t have strong prior beleifs, then the view (at least amongst many ecologists) was that it was most cautious to use a highly uninformative prior like the good old Winbugs gamma(0.01, 0.01) prior that was used for precision parameters.
Now the experts are encouraging us to use weakly informative priors, even when little prior evidence is available. The case being that too broad a prior can slow computations and result in ridiculous results. Consider the broad gamma(0.01, 0.01) prior: it amounts to giving equal weight to a standard deviation of 1 as it does to an SD of 10000. The end result is that this ‘uninformative prior’ can bias your estimates of the SD to be too high.
As demonstrated here, another nice feature of informative priors is they can be used to control ‘shrinkage’. Here by varying theta1 we could shrink our model fit towards a base case model (e.g. a null hypothesis) that had no temporal variation.
If you are interested to learn more, it is worth reading at least the Introduction of Simpson et al. Penalized Complexity Priors pub. Other good general guidance can be found on the STAN wiki.
There is clearly a lot more fun we can have by playing around with priors. I anticipate that applied scientists, like my ecological colleagues, will soon start paying much more attention to prior choice.